(the 2016 update to this post can be found at: https://medium.com/@shivon/the-current-state-of-machine-intelligence-2-0-a9e0bab95511#.ffmh59x3o)
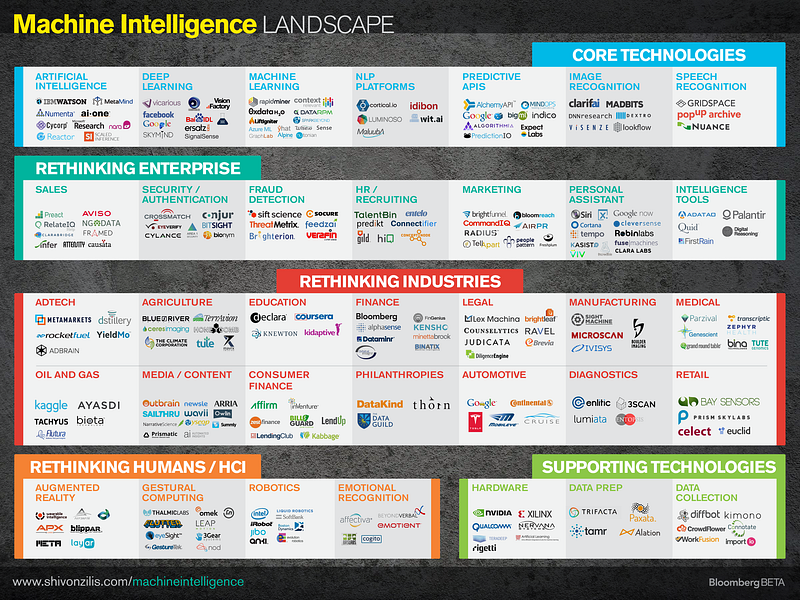
I spent the last three months learning about every artificial intelligence, machine learning, or data related startup I could find — my current list has 2,529 of them to be exact. Yes, I should find better things to do with my evenings and weekends but until then…
Why do this?
A few years ago, investors and startups were chasing “big data” (I helped put together a landscape on that industry). Now we’re seeing a similar explosion of companies calling themselves artificial intelligence, machine learning, or somesuch — collectively I call these “machine intelligence” (I’ll get into the definitions in a second). Our fund, Bloomberg Beta, which is focused on the future of work, has been investing in these approaches. I created this landscape to start to put startups into context. I’m a thesis-oriented investor and it’s much easier to identify crowded areas and see white space once the landscape has some sort of taxonomy.
What is “machine intelligence,” anyway?
I mean “machine intelligence” as a unifying term for what others call machine learning and artificial intelligence. (Some others have used the term before, without quite describing it or understanding how laden this field has been with debates over descriptions.) I would have preferred to avoid a different label but when I tried either “artificial intelligence” or “machine learning” both proved to too narrow: when I called it “artificial intelligence” too many people were distracted by whether certain companies were “true AI,” and when I called it “machine learning,” many thought I wasn’t doing justice to the more “AI-esque” like the various flavors of deep learning. People have immediately grasped “machine intelligence” so here we are. ☺
Computers are learning to think, read, and write. They’re also picking up human sensory function, with the ability to see and hear (arguably to touch, taste, and smell, though those have been of a lesser focus). Machine intelligence technologies cut across a vast array of problem types (from classification and clustering to natural language processing and computer vision) and methods (from support vector machines to deep belief networks). All of these technologies are reflected on this landscape.
What this landscape doesn’t include, however important, is “big data” technologies. Some have used this term interchangeably with machine learning and artificial intelligence, but I want to focus on the intelligence methods rather than data, storage, and computation pieces of the puzzle for this landscape (though of course data technologies enable machine intelligence).
Which companies are on the landscape?
I considered thousands of companies, so while the chart is crowded it’s still a small subset of the overall ecosystem. “Admissions rates” to the chart were fairly in line with those of Yale or Harvard, and perhaps equally arbitrary. ☺
I tried to pick companies that used machine intelligence methods as a defining part of their technology. Many of these companies clearly belong in multiple areas but for the sake of simplicity I tried to keep companies in their primary area and categorized them by the language they use to describe themselves (instead of quibbling over whether a company used “NLP” accurately in its self-description).
If you want to get a sense for innovations at the heart of machine intelligence, focus on the core technologies layer. Some of these companies have APIs that power other applications, some sell their platforms directly into enterprise, some are at the stage of cryptic demos, and some are so stealthy that all we have is a few sentences to describe them.
The most exciting part for me was seeing how much is happening in the application space. These companies separated nicely into those that reinvent the enterprise, industries, and ourselves.
If I were looking to build a company right now, I’d use this landscape to help figure out what core and supporting technologies I could package into a novel industry application. Everyone likes solving the sexy problems but there are an incredible amount of ‘unsexy’ industry use cases that have massive market opportunities and powerful enabling technologies that are begging to be used for creative applications (e.g., Watson Developer Cloud, AlchemyAPI).
Reflections on the landscape:
We’ve seen a few great articles recently outlining why machine intelligence is experiencing a resurgence, documenting the enabling factors of this resurgence. (Kevin Kelly, for example chalks it up to cheap parallel computing, large datasets, and better algorithms.) I focused on understanding the ecosystem on a company-by-company level and drawing implications from that.
Yes, it’s true, machine intelligence is transforming the enterprise, industries and humans alike.
On a high level it’s easy to understand why machine intelligence is important, but it wasn’t until I laid out what many of these companies are actually doing that I started to grok how much it is already transforming everything around us. As Kevin Kelly more provocatively put it, “the business plans of the next 10,000 startups are easy to forecast: Take X and add AI”. In many cases you don’t even need the X — machine intelligence will certainly transform existing industries, but will also likely create entirely new ones.
Machine intelligence is enabling applications we already expect like automated assistants (Siri), adorable robots (Jibo), and identifying people in images (like the highly effective but unfortunately named DeepFace). However, it’s also doing the unexpected: protecting children from sex trafficking, reducing the chemical content in the lettuce we eat, helping us buy shoes online that fit our feet precisely, and destroying 80’s classic video games.
Many companies will be acquired.
I was surprised to find that over 10% of the eligible (non-public) companies on the slide have been acquired. It was in stark contrast to big data landscape we created, which had very few acquisitions at the time.
No jaw will drop when I reveal that Google is the number one acquirer, though there were more than 15 different acquirers just for the companies on this chart. My guess is that by the end of 2015 almost another 10% will be acquired. For thoughts on which specific ones will get snapped up in the next year you’ll have to twist my arm…
Big companies have a disproportionate advantage, especially those that build consumer products.
The giants in search (Google, Baidu), social networks (Facebook, LinkedIn, Pinterest), content (Netflix, Yahoo!), mobile (Apple) and e-commerce (Amazon) are in an incredible position. They have massive datasets and constant consumer interactions that enable tight feedback loops for their algorithms (and these factors combine to create powerful network effects) — and they have the most to gain from the low hanging fruit that machine intelligence bears.
Best-in-class personalization and recommendation algorithms have enabled these companies’ success (it’s both impressive and disconcerting that Facebook recommends you add the person you had a crush on in college and Netflix tees up that perfect guilty pleasure sitcom). Now they are all competing in a new battlefield: the move to mobile. Winning mobile will require lots of machine intelligence: state of the art natural language interfaces (like Apple’s Siri), visual search (like Amazon’s “FireFly”), and dynamic question answering technology that tells you the answer instead of providing a menu of links (all of the search companies are wrestling with this).Large enterprise companies (IBM and Microsoft) have also made incredible strides in the field, though they don’t have the same human-facing requirements so are focusing their attention more on knowledge representation tasks on large industry datasets, like IBM Watson’s application to assist doctors with diagnoses.
The talent’s in the New (AI)vy League.
In the last 20 years, most of the best minds in machine intelligence (especially the ‘hardcore AI’ types) worked in academia. They developed new machine intelligence methods, but there were few real world applications that could drive business value.
Now that real world applications of more complex machine intelligence methods like deep belief nets and hierarchical neural networks are starting to solve real world problems, we’re seeing academic talent move to corporate settings. Facebook recruited NYU professors Yann LeCun and Rob Fergus to their AI Lab, Google hired University of Toronto’s Geoffrey Hinton, Baidu wooed Andrew Ng. It’s important to note that they all still give back significantly to the academic community (one of LeCun’s lab mandates is to work on core research to give back to the community, Hinton spends half of his time teaching, Ng has made machine intelligence more accessible through Coursera) but it is clear that a lot of the intellectual horsepower is moving away from academia.
For aspiring minds in the space, these corporate labs not only offer lucrative salaries and access to the “godfathers” of the industry, but, the most important ingredient: data. These labs offer talent access to datasets they could never get otherwise (the ImageNet dataset is fantastic, but can’t compare to what Facebook, Google, and Baidu have in house). As a result, we’ll likely see corporations become the home of many of the most important innovations in machine intelligence and recruit many of the graduate students and postdocs that would have otherwise stayed in academia.
There will be a peace dividend.
Big companies have an inherent advantage and it’s likely that the ones who will win the machine intelligence race will be even more powerful than they are today. However, the good news for the rest of the world is that the core technology they develop will rapidly spill into other areas, both via departing talent and published research.
Similar to the big data revolution, which was sparked by the release of Google’s BigTable and BigQuery papers, we will see corporations release equally groundbreaking new technologies into the community. Those innovations will be adapted to new industries and use cases that the Googles of the world don’t have the DNA or desire to tackle.
Opportunities for entrepreneurs:
“My company does deep learning for X”
Few words will make you more popular in 2015. That is, if you can credibly say them.
Deep learning is a particularly popular method in the machine intelligence field that has been getting a lot of attention. Google, Facebook, and Baidu have achieved excellent results with the method for vision and language based tasks and startups like Enlitic have shown promising results as well.
Yes, it will be an overused buzzword with excitement ahead of results and business models, but unlike the hundreds of companies that say they do “big data”, it’s much easier to cut to the chase in terms of verifying credibility here if you’re paying attention.
The most exciting part about the deep learning method is that when applied with the appropriate levels of care and feeding, it can replace some of the intuition that comes from domain expertise with automatically-learned features. The hope is that, in many cases, it will allow us to fundamentally rethink what a best-in-class solution is.
As an investor who is curious about the quirkier applications of data and machine intelligence, I can’t wait to see what creative problems deep learning practitioners try to solve. I completely agree with Jeff Hawkins when he says a lot of the killer applications of these types of technologies will sneak up on us. I fully intend to keep an open mind.
“Acquihire as a business model”
People say that data scientists are unicorns in short supply. The talent crunch in machine intelligence will make it look like we had a glut of data scientists. In the data field, many people had industry experience over the past decade. Most hardcore machine intelligence work has only been in academia. We won’t be able to grow this talent overnight.
This shortage of talent is a boon for founders who actually understand machine intelligence. A lot of companies in the space will get seed funding because there are early signs that the acquihire price for a machine intelligence expert is north of 5x that of a normal technical acquihire (take, for example Deep Mind, where price per technical head was somewhere between $5–10M, if we choose to consider it in the acquihire category). I’ve had multiple friends ask me, only semi-jokingly, “Shivon, should I just round up all of my smartest friends in the AI world and call it a company?” To be honest, I’m not sure what to tell them. (At Bloomberg Beta, we’d rather back companies building for the long term, but that doesn’t mean this won’t be a lucrative strategy for many enterprising founders.)
A good demo is disproportionately valuable in machine intelligence
I remember watching Watson play Jeopardy. When it struggled at the beginning I felt really sad for it. When it started trouncing its competitors I remember cheering it on as if it were the Toronto Maple Leafs in the Stanley Cup finals (disclaimers: (1) I was an IBMer at the time so was biased towards my team (2) the Maple Leafs have not made the finals during my lifetime — yet — so that was purely a hypothetical).
Why do these awe-inspiring demos matter? The last wave of technology companies to IPO didn’t have demos that most of us would watch, so why should machine intelligence companies? The last wave of companies were very computer-like: database companies, enterprise applications, and the like. Sure, I’d like to see a 10x more performant database, but most people wouldn’t care. Machine intelligence wins and loses on demos because 1) the technology is very human, enough to inspire shock and awe, 2) business models tend to take a while to form, so they need more funding for longer period of time to get them there, 3) they are fantastic acquisition bait.
Watson beat the world’s best humans at trivia, even if it thought Toronto was a US city. DeepMind blew people away by beating video games. Vicarious took on CAPTCHA. There are a few companies still in stealth that promise to impress beyond that, and I can’t wait to see if they get there.
Demo or not, I’d love to talk to anyone using machine intelligence to change the world. There’s no industry too unsexy, no problem too geeky. I’d love to be there to help so don’t be shy.
I hope this landscape chart sparks a conversation. The goal to is make this a living document and I want to know if there are companies or categories missing. I welcome feedback and would like to put together a dynamic visualization where I can add more companies and dimensions to the data (methods used, data types, end users, investment to date, location, etc.) so that folks can interact with it to better explore the space.













 One common scenario; un-categorized DDoS bot with a spoofed IE6 user-agent.
One common scenario; un-categorized DDoS bot with a spoofed IE6 user-agent.